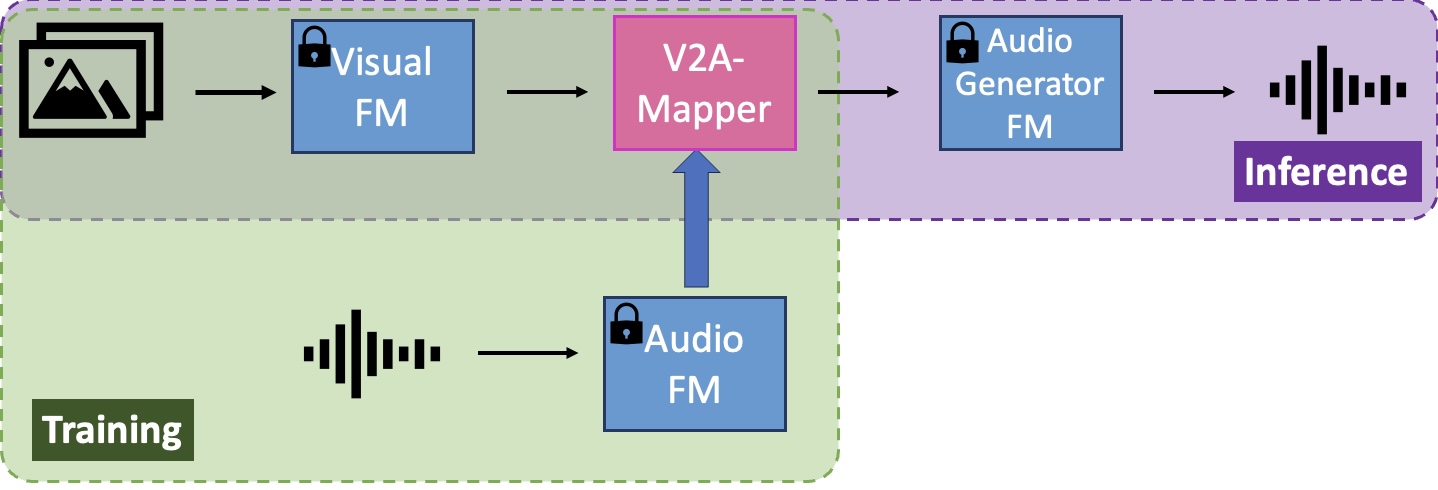
Building artificial intelligence (AI) systems on top of a set of foundation models (FMs) is becoming a new paradigm in AI research. Their representative and generative abilities learnt from vast amounts of data can be easily adapted and transferred to a wide range of downstream tasks without extra training from scratch. However, leveraging FMs in cross-modal generation remains under-researched when audio modality is involved.
On the other hand, automatically generating semantically-relevant sound from visual input is an important problem in cross-modal generation studies. To solve this vision-to-audio (V2A) generation problem, existing methods tend to design and build complex systems from scratch using modestly sized datasets.
In this project, we propose a lightweight solution to this problem by leveraging foundation models, specifically CLIP, CLAP, and AudioLDM. We first investigate the domain gap between the latent space of the visual CLIP and the auditory CLAP models. Then we propose a simple yet effective mapper mechanism V2A-Mapper to bridge the domain gap by translating the visual input between CLIP and CLAP spaces. Conditioned on the translated CLAP embedding, pretrained audio generative FM AudioLDM is adopted to produce high-fidelity and visually-aligned sound. Compared to previous approaches, our method only requires a quick training of the V2A-Mapper. We further analyze and conduct extensive experiments on the choice of the V2A-Mapper and show that a generative mapper is better at fidelity and variability (FD) while a regression mapper is slightly better at relevance (CS). Both objective and subjective evaluation on two V2A datasets demonstrate the superiority of our proposed method compared to current state-of-the-art approaches - trained with 86% fewer parameters but achieving 53% and 19% improvement in FD and CS, respectively.
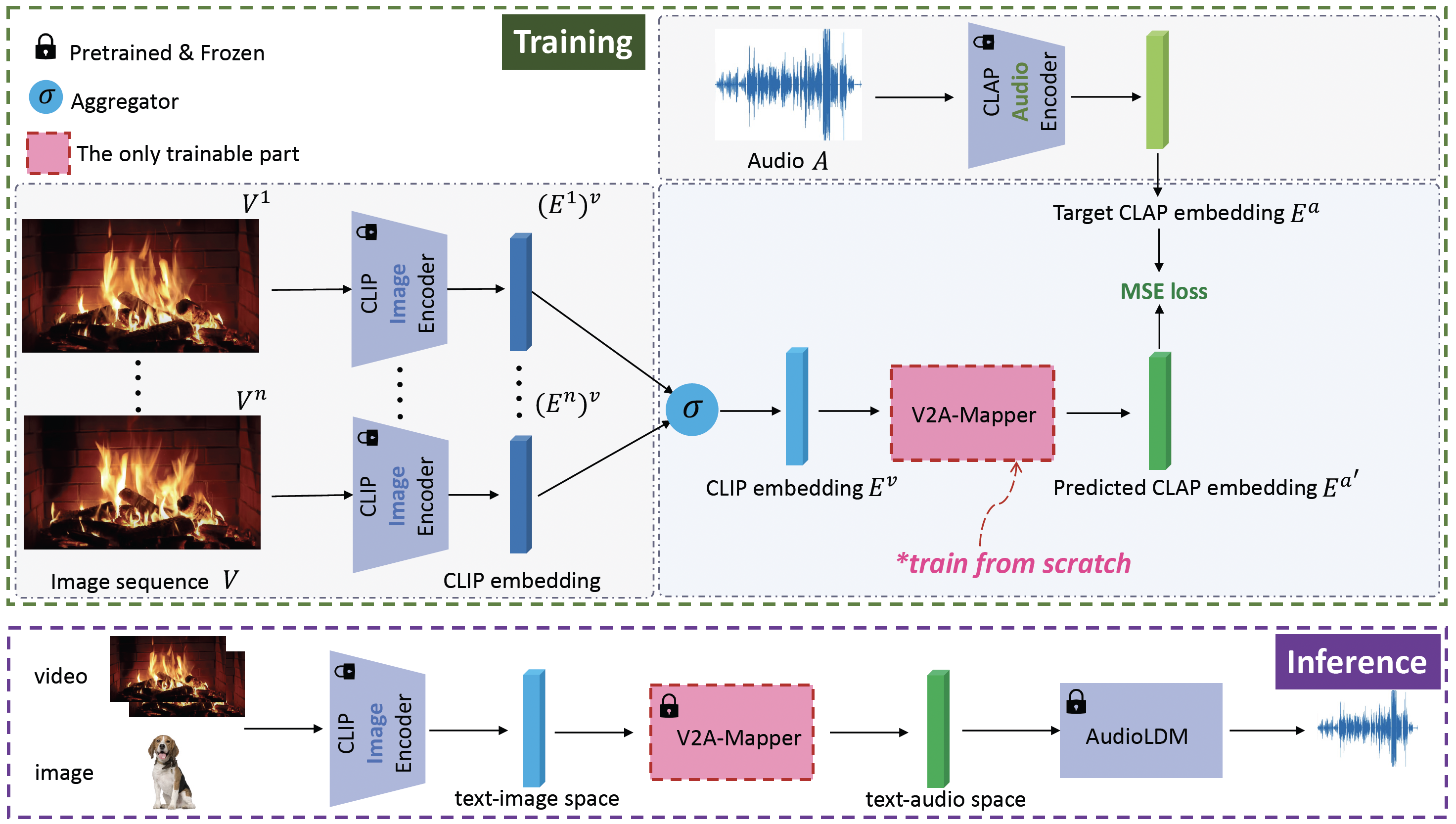
Our lightweight method only requires the training of a V2A-Mapper to bridge the domain gap between the vision representative FM CLIP and the audio generative FM AudioLDM. The V2A-Mapper is supervised by the audio representative FM CLAP to learn the translation from visual space to auditory space. Leveraging the generalization and knowledge transfer ability of foundation models, the V2A-Mapper is trained with the same modestly sized dataset but the overall system can achieve much better performance.
Our V2A-Mapper helps synthesize high-fidelity and visually-relevant sound based on images/videos.
The first three images are generated with Midjourney and the last one is a cat meme.




We compare our method with previous works including Im2Wav1, CLIPSonic-IQ2, and Make-An-Audio3. We generate 10-second audio clips for all the evaluation. Our method can synthesize different categories of audio sound from in-the-wild images.
ImageHear1 contains 101 images from 30 visual classes (2-8 images per class). We show comparison with Im2Wav and CLIPSonic-IQ with samples from ImageHear here.
 Im2Wav
ClipSonic-IQ
Ours
Im2Wav
ClipSonic-IQ
Ours
 Im2Wav
ClipSonic-IQ
Ours
Im2Wav
ClipSonic-IQ
Ours
 Im2Wav
ClipSonic-IQ
Ours
Im2Wav
ClipSonic-IQ
Ours
 Im2Wav
ClipSonic-IQ
Ours
Im2Wav
ClipSonic-IQ
Ours
 Im2Wav
ClipSonic-IQ
Ours
Im2Wav
ClipSonic-IQ
Ours
 Im2Wav
ClipSonic-IQ
Ours
Im2Wav
ClipSonic-IQ
Ours
 Im2Wav
ClipSonic-IQ
Ours
Im2Wav
ClipSonic-IQ
Ours
 Im2Wav
ClipSonic-IQ
Ours
Im2Wav
ClipSonic-IQ
Ours
 Im2Wav
ClipSonic-IQ
Ours
Im2Wav
ClipSonic-IQ
Ours
We also compare with Make-An-Audio. The audio clips generated by Make-An-Audio and the image samples are extracted from their project website.
 Ours
Make-An-Audio
Ours
Make-An-Audio
 Ours
Make-An-Audio
Ours
Make-An-Audio
 Ours
Make-An-Audio
Ours
Make-An-Audio
 Ours
Make-An-Audio
Ours
Make-An-Audio
 Ours
Make-An-Audio
Ours
Make-An-Audio
 Ours
Make-An-Audio
Ours
Make-An-Audio
We compare our method with previous works including Im2Wav1, CLIPSonic-IQ2, and Make-An-Audio3. We generate 10-second audio clips for all the evaluation. Our method can synthesize matching sound for videos captured in real-world scenarios.
VGGSound4 contains 199,176 10-second video clips extracted from videos uploaded to YouTube with audio-visual correspondence. Like Im2Wav and CLIPSonic-IQ, we train our V2A-Mapper with VGGSound only. Our method generalizes better to unseen videos compared to other approaches. Note the Foundation Models we use have never been trained on VGGSound. VGGSound contains noisy data whose audio and visual streams might not be highly-relevant. To observe how our method is robust to noisy training data, please watch the sports live video.
(the sports live video)
We also compare with Make-An-Audio. The audio clips generated by Make-An-Audio and the video samples are extracted from their project website.
We present three audio clips generated from the same visual input to showcase the diversity of our method. Since our V2A-Mapper is a diffusion-based generative model, it is capable of modeling one-to-many relationships.
For the same image, our method is capable of generating different but visually-relevant audio clips.
 Sample 1
Sample 2
Sample 3
Sample 1
Sample 2
Sample 3
 Sample 1
Sample 2
Sample 3
Sample 1
Sample 2
Sample 3
 Sample 1
Sample 2
Sample 3
Sample 1
Sample 2
Sample 3
 Sample 1
Sample 2
Sample 3
Sample 1
Sample 2
Sample 3
 Sample 1
Sample 2
Sample 3
Sample 1
Sample 2
Sample 3
 Sample 1
Sample 2
Sample 3
Sample 1
Sample 2
Sample 3
For the same video, our method is capable of generating different but visually-relevant audio clips.
Thanks to the V2A-Mapper, our method supports interpolation along the latent space guided by either visual or textual prompt. We show the process by interleaving ten 3-second intermediate audio clips with 1-second pause. We generate 10-second sound but just present the first three seconds to observe the transition.
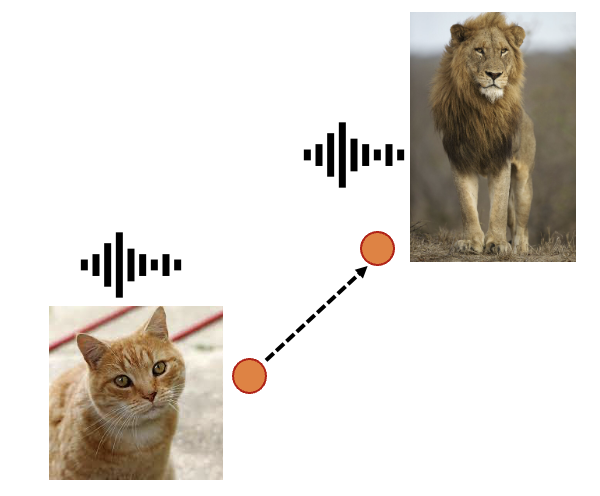 cat to lion
cat to lion
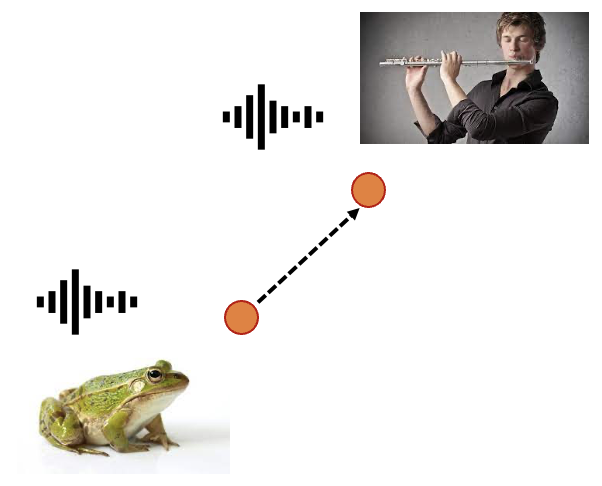 frog to flute
frog to flute
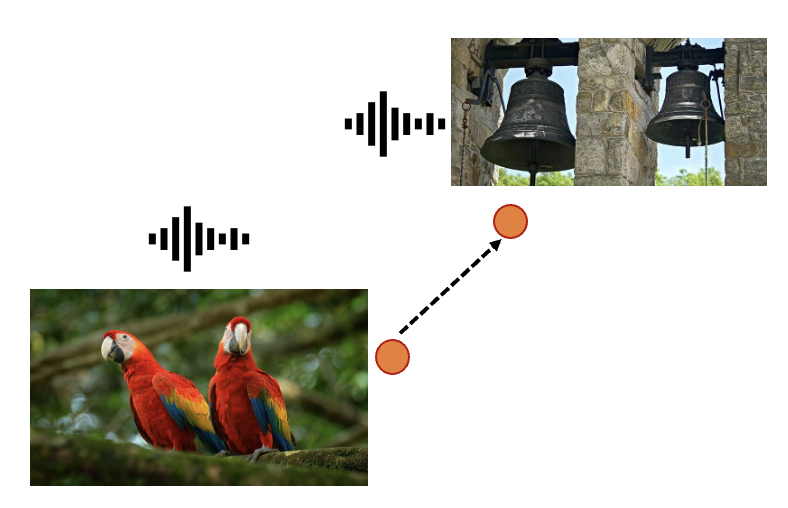 bird to bell
bird to bell
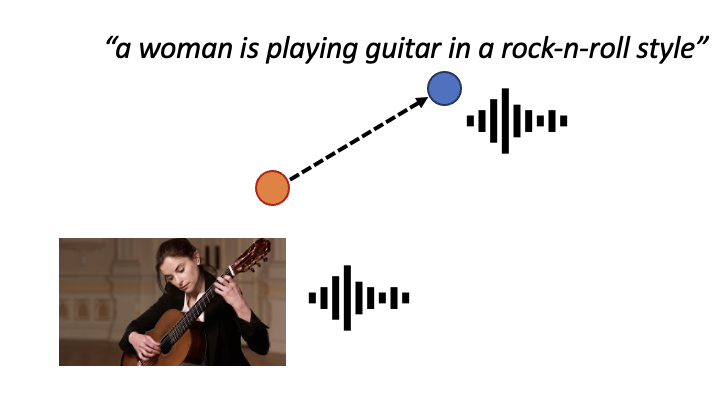 guitar to rock style
guitar to rock style
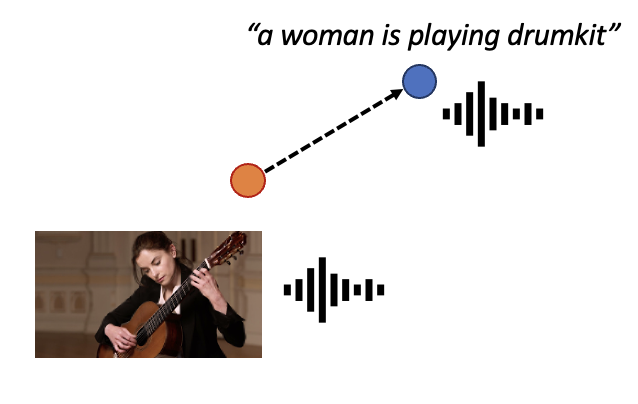 guitar to drum
guitar to drum
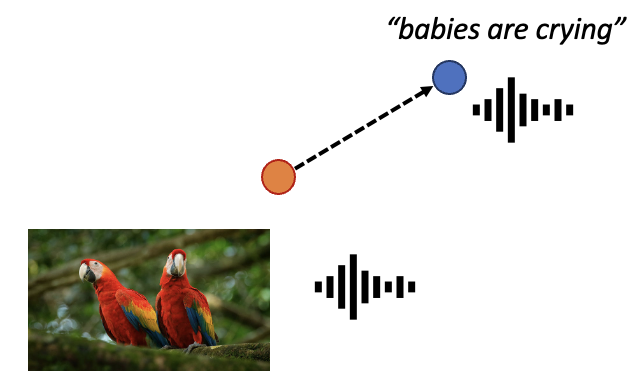 bird to crying baby
bird to crying baby
In this section, we demonstrate the proposed V2A-Mapper can bridge the domain gap between vision and audio spaces. If the mapper is absent (w/o the mapper), directly conditioning the audio generator with CLIP embeddings (i.e., the visual features) would lead to random and nonsense results. The examples below demonstrate the CLIP space is not understandable by the audio generator. After placing the proposed V2A-Mapper in between (w/ the mapper), we can observe that the generated sound makes much more sense. With the mapper, the vision space has been converted into the corresponding auditory space which can be interpreted by the audio generator.
 w/o the mapper
w/ the mapper
w/o the mapper
w/ the mapper
 w/o the mapper
w/ the mapper
w/o the mapper
w/ the mapper
 w/o the mapper
w/ the mapper
w/o the mapper
w/ the mapper
In this section, we demonstrate why using a captioner to generate description and then apply text-to-audio generator is not an optimal solution to the vision-to-audio synthesis problem. Given available image-to-text (e.g. BLIP) and text-to-audio (e.g. AudioLDM) generation systems, it is intuitive to adopt a vision-text-audio pipeline to solve the vision-to-audio synthesis task without any training. However, we observe that this intuitive solution is bottlenecked by the performance of the captioner. As shown below, if BLIP fails at predicting the object (drum set instead of bongo; flute instead of harmonica), the sound output would also be wrong.
 vision-text-audio w/ BLIP-generated captions
"a man sitting in front of a drum set"
w/ mapper
vision-text-audio w/ BLIP-generated captions
"a man sitting in front of a drum set"
w/ mapper
 vision-text-audio w/ BLIP-generated captions
"a man with dreadlocks playing a flute"
w/ mapper
vision-text-audio w/ BLIP-generated captions
"a man with dreadlocks playing a flute"
w/ mapper
@inproceedings{v2a-mapper,
title = {V2A-Mapper: A Lightweight Solution for Vision-to-Audio Generation by Connecting Foundation Models},
author = {Wang, Heng and Ma, Jianbo and Pascual, Santiago and Cartwright, Richard and Cai, Weidong},
booktitle = {Proceedings of the AAAI Conference on Artificial Intelligence},
year = {2024},
}Roy Sheffer and Yossi Adi, "I Hear Your True Colors: Image Guided Audio Generation," Proc. ICASSP, 2023. ↩
Hao-Wen Dong et al., "CLIPSonic: Text-to-Audio Synthesis with Unlabeled Videos and Pretrained Language-Vision Models," arXiv preprint arXiv:2306.09635, 2023.↩
Rongjie Huang et al., "Make-An-Audio: Text-to-Audio Generation with Prompt-enhanced Diffusion Models," Proc. ICML, 2023.↩
Honglie Chen et al., "VGGSound: A Large-scale Audio-Visual Dataset," Proc. ICASSP, 2020↩